+++
title = "データサイエンス入門講座で学んだことをまとめます"
date = 2020-05-16T20:12:22+08:00
Description = "データサイエンティスト入門講座を受講していて学んだことをまとめてみましたよ。"
Tags = []
Categories = ["python", "jupyter"]
+++
「[【ゼロから始めるデータ分析】 ビジネスケースで学ぶPythonデータサイエンス入門](https://www.udemy.com/course/optworks_1/)」で統計について学んだことをここにまとめていきます。
## 前提
[【Practice】Boxed Lunch Sales Forecasting | SIGNATE - Data Science Competition](https://signate.jp/competitions/24)で入手できる、以下のような表データを例に取り上げて見ていきます:
 ## 基本統計量について
[基本統計量 | トライフィールズ](https://www.trifields.jp/statistical-analysis-basic-statistics-164)によれば、
> 基本統計量とは、データの基本的な特徴を表す値のことで、代表値と散布度に区分できる。代表値とは、データを代表するような値のことで、例えば、平均値、最大値、最小値などがある。散布度とは、データの散らばり度合いを表すような値のことで、例えば、分散、標準偏差などがある。
とのこと。
今回は`Python`のライブラリ`Pandas`を用いて基本統計量を確認していきます。
### Pandasで出力される基本統計量について
`describe()`を実行すると、以下の要素が出力されます:
## 基本統計量について
[基本統計量 | トライフィールズ](https://www.trifields.jp/statistical-analysis-basic-statistics-164)によれば、
> 基本統計量とは、データの基本的な特徴を表す値のことで、代表値と散布度に区分できる。代表値とは、データを代表するような値のことで、例えば、平均値、最大値、最小値などがある。散布度とは、データの散らばり度合いを表すような値のことで、例えば、分散、標準偏差などがある。
とのこと。
今回は`Python`のライブラリ`Pandas`を用いて基本統計量を確認していきます。
### Pandasで出力される基本統計量について
`describe()`を実行すると、以下の要素が出力されます:
 ここの要素の説明は以下になります:
- `count`: 要素の個数
- `mean`: 算術平均
- `std`: 標準偏差
- `min`: 最小値
- `25%`, `75%`: 1/4分位数、3/4分位数
- `50%`: 中央値(median)
- `max`: 最大値
#### 要素の個数について (count)
そのデータの個数を示します。ライブラリの`Pandas`が空データと判断したものは除外して表示してくれています。
上の実行結果で、例えば`y`に注目すると、空ではないデータが207個あることがわかります。
#### 平均について (mean)
要素の平均を示します。
上の実行結果で、例えば`y`に注目すると、`y`の平均は86.623188であることがわかります。
#### 標準偏差について (std)
標準偏差を求めます。高校で数学を学んでいたときは理解できていなかったのですが、標準偏差というのは「平均 ± 標準偏差」の範囲に大体のデータが集中している…というように読むものだそうです。知らなかったです。
上の実行結果で、例えば`y`に注目すると、`y`の大体のデータは54〜118の範囲に分布しているというように読むようです。
#### 最小値 (min), 最大値 (max), 中央値 (50%)について
最小値は一番小さな値。最大値は一番大きな値。中央値は真ん中の値。
中央値は平均とは違い、データの個数で割るということをしていないので、純粋に真ん中の値になることに注意が必要です。
#### 25%, 75%について
25% (percentile)は最小値から数えて25%に位置する値のこと。75% (percentile)は最小値から数えて75%に位置する値のことです。
こちらも平均とは異なるので注意。
## グラフについて
知らなかったグラフをまとめるよ。
### ヒストグラム
ヒストグラムはこんな感じのグラフです。一つの列に注目して頻度の分布を求めるために使うようです:
ここの要素の説明は以下になります:
- `count`: 要素の個数
- `mean`: 算術平均
- `std`: 標準偏差
- `min`: 最小値
- `25%`, `75%`: 1/4分位数、3/4分位数
- `50%`: 中央値(median)
- `max`: 最大値
#### 要素の個数について (count)
そのデータの個数を示します。ライブラリの`Pandas`が空データと判断したものは除外して表示してくれています。
上の実行結果で、例えば`y`に注目すると、空ではないデータが207個あることがわかります。
#### 平均について (mean)
要素の平均を示します。
上の実行結果で、例えば`y`に注目すると、`y`の平均は86.623188であることがわかります。
#### 標準偏差について (std)
標準偏差を求めます。高校で数学を学んでいたときは理解できていなかったのですが、標準偏差というのは「平均 ± 標準偏差」の範囲に大体のデータが集中している…というように読むものだそうです。知らなかったです。
上の実行結果で、例えば`y`に注目すると、`y`の大体のデータは54〜118の範囲に分布しているというように読むようです。
#### 最小値 (min), 最大値 (max), 中央値 (50%)について
最小値は一番小さな値。最大値は一番大きな値。中央値は真ん中の値。
中央値は平均とは違い、データの個数で割るということをしていないので、純粋に真ん中の値になることに注意が必要です。
#### 25%, 75%について
25% (percentile)は最小値から数えて25%に位置する値のこと。75% (percentile)は最小値から数えて75%に位置する値のことです。
こちらも平均とは異なるので注意。
## グラフについて
知らなかったグラフをまとめるよ。
### ヒストグラム
ヒストグラムはこんな感じのグラフです。一つの列に注目して頻度の分布を求めるために使うようです:
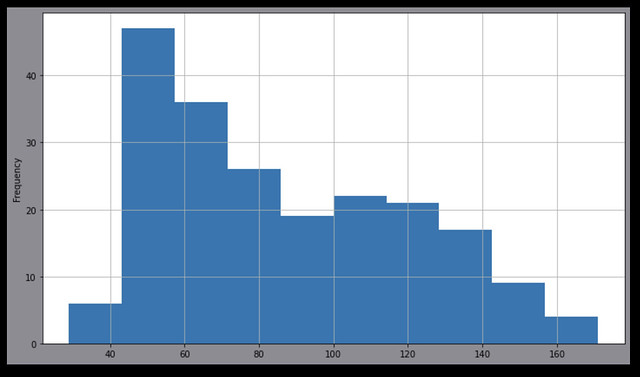 このグラフを見ると、40〜60の値をとっているデータの個数が一番多いということがわかります。注目している列の基本統計量を見ると、このようになっています:
y軸の合計が207。「平均値±標準偏差」の区間に大体のデータが集約されているので、54〜118の区間に大体のデータが集まっている。平均は86で、中央値は78。
この基本統計量から読み取れる情報と、実際にグラフ化してみて分かる情報は結構違うなぁと思いました。
### 箱ヒゲ図
箱ヒゲ図は2つの列に注目して、関係を調べるために利用するようです。株の投資とかでよく見かけるグラフですが、正直見方をわかっていませんでした。。このように見ればいいようです:
このグラフを見ると、40〜60の値をとっているデータの個数が一番多いということがわかります。注目している列の基本統計量を見ると、このようになっています:
y軸の合計が207。「平均値±標準偏差」の区間に大体のデータが集約されているので、54〜118の区間に大体のデータが集まっている。平均は86で、中央値は78。
この基本統計量から読み取れる情報と、実際にグラフ化してみて分かる情報は結構違うなぁと思いました。
### 箱ヒゲ図
箱ヒゲ図は2つの列に注目して、関係を調べるために利用するようです。株の投資とかでよく見かけるグラフですが、正直見方をわかっていませんでした。。このように見ればいいようです:
 曜日ごとに分類した場合に、木曜日は50後半〜100の間に多くのデータが分布していて、特定のロジックに基づいて外れ値を検出などもしつつ適切な範囲の最小値と最大値を求めているようです。このため、箱ヒゲ図の最小値と最大値は基本統計量とは異なるようです。
### 散布図
二つの列に注目して、一方が増えると、他方がどうなるかといった関係 (= 相関関係と呼ぶみたい)を調べる図だそうです。
曜日ごとに分類した場合に、木曜日は50後半〜100の間に多くのデータが分布していて、特定のロジックに基づいて外れ値を検出などもしつつ適切な範囲の最小値と最大値を求めているようです。このため、箱ヒゲ図の最小値と最大値は基本統計量とは異なるようです。
### 散布図
二つの列に注目して、一方が増えると、他方がどうなるかといった関係 (= 相関関係と呼ぶみたい)を調べる図だそうです。
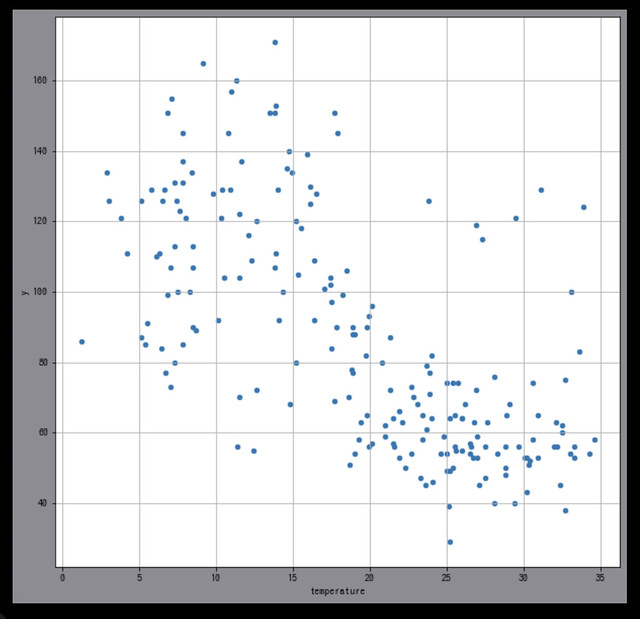 このグラフは2つのデータはあんまり関係ない…と読むみたい。
## まとめ
基本的な概念を学ぶことで読み方がわかってきましたよ。
このグラフは2つのデータはあんまり関係ない…と読むみたい。
## まとめ
基本的な概念を学ぶことで読み方がわかってきましたよ。