8.7 KiB
| title | author | date | url | wordtwit_posted_tweets | wordtwit_post_info | tmac_last_id | categories | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Systems Performance: Enterprise and the Cloud を読む | kazu634 | 2014-10-31 | /2014/10/31/reading-systems-performance-enterprise-and-the-cloud/ |
|
|
|
|
Systems Performance: Enterprise and the Cloudを読んでいます。システム管理の分野で顕著な成果として2013年度のLISA Awardというのを受賞した書籍らしいのですが、これがまた面白い。たぶん自分が何を説明しているのかを正確に理解している人が、わかりやすく伝える努力を惜しまずに書くとこんな書籍になるのだと思う。これは最後まで読まねば。
著者の人のスライドを発見したので貼り付け:
とりあえず気になった部分をまとめていきます。随時更新。
更新履歴:
- 2014/10/31: Introductionの途中までメモ
- 2014/11/01: Methodologyの途中までメモ

Systems Performance: Enterprise and the Cloud
Introduction
冒頭、ドナルド・ラムズフェルドの発言を引用して始まります:
There are known knowns; there are thing we know we know. We also know there are known unknowns; that is to say we know there are some things we do not know. But there are also unknown unknowns — there are things we do not know we do not know.
— U.S. Secretary of Defense Donald Rumsfeld, Feb 12, 2002
この書籍で扱う Performance は、”unknown unknowns”、「つまり知らないことすら認識していないこと」だと述べていく。この出だしだけで、この書籍が巧みに読者の興味をくすぐっている事がわかるかと思う。
Performance is challenging
パフォーマンスに関する問題が難しい理由を3つ挙げて解説している。
Performance is subjective
パフォーマンスに関する問題は主観的なものであり、明確なゴールを設定せずには客観的にはなりえない。たとえば、平均レスポンスタイムを設定したり、一定の割合のリクエストが特定のレイテンシの範囲におさまるなどというように。
Systems are complex
複雑なパフォーマンス上の問題を解決するためには、ホリスティックなアプローチが必要となることが多い。システム全体、つまりシステム内部と外部間の接続を調査する必要がある。こうした調査を実施するためには、幅広いスキルが必要になる。必要とされるスキルの範囲が広く、一人のエンジニアがこうしたスキルをすべて持つことはあまり無い。また、システム全体を調査する必要があるために、パフォーマンス上の問題解決は多種多様であり、困難な問題となる。
There can be multiple performance issue
パフォーマンス上の問題はいたるところにあり、実際にやるべきタスクはボトルネックになっている問題を特定することだ。
Chapter 2: Methodology
冒頭、シャーロック・ホームズからの引用で始まりました:
It is capital mistake to theorize before one has data. Insensibly one begins to twist facts to suit theories, instead of theories to suit facts.
— Sherlock Holmes in “A Scandal in Bohemia” by Sir Arthur Conan Doyle
データーを入手する前に理屈付けるのは大きな誤りだ。気付かないうちに、事実に合わせて陸続けるのではなくて、理屈に合わせて事実をねじ曲げることになるから……というこれまた的確な引用といえるかと。
Termiology
IOPS
Input/Output operations per second is a measure of the rate of data transfer operation.
Throughput
The rate of work performed. Especially in communications, the term is used to refer to the data rate (byte per second or bit per second).
Responsetime
The time for an operation to complete. This includes any time spent waiting and time spent being serviced (service time), including the time to transfer the result.
Latency
A measure of time an operation spends waiting to be serviced.
Utilization
For resources that service requests, utilization is a measure of how busy a resource is, based on how much time in a given interval it was actively performing work.
Saturation
The degree to which a resource has queued work it cannot service.
Bottleneck
In system performance, a bottleneck is a resource that limits the performance of the system. Identifying and removing systematic bottlenecks is a key activity of system performance.
workload
The input to the system or the load applied is the workload.
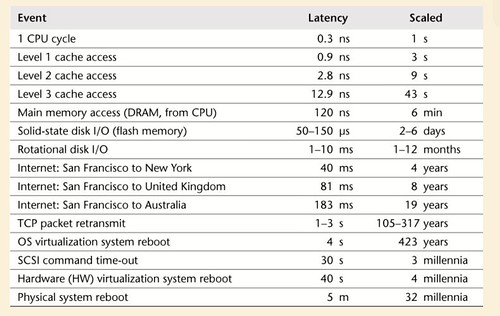
CPU視点でみた場合の各パーツの処理に要する時間とわかりやすい卑近な例に例えたら
こんな感じの表が掲載されていました:
CPUからするとSSDすらかなり遅いんですね。。。